Stable Diffusion - Model Training
ตัวอย่างจะเน้นการฝึกภาพบุคคล
เตรียมภาพเพื่อฝึกโมเดล
สมมุติว่าต้องการฝึกหน้าคน เช่นนาย A ให้เตรียมภาพไว้อย่างน้อย 10-20 รูป ก็เพียงพอโดย
- เน้นภาพคม ๆ คุณภาพสูง noise ไม่เยอะ
- พื้นหลังและสภาพแสงหลาย ๆ แบบ
- หลากหลายมุมไม่ใช่หน้าตรงอย่างเดียว เงยหน้า ก้มหน้า หันข้าง ได้หมด
ภาพยิ่งเยอะยิ่งใช้เวลาฝึกนาน
หลังจากนั้นให้ resize ให้มีขนาด 512*512 โดยใช้โปรแกรมที่ถนัด หรือใช้
https://www.birme.net/?target_width=512&target_height=512
โดย resize ให้บุคคลอยู่ตรงกลางภาพหลังจากนั้นจึงจับใส่ folder ให้เรียบร้อยเช่น
D:\AI\Model\ชื่อ folder
สร้าง caption
เปิด Stable Diffusion แล้วไปที่ Train > Preprocess images
Source directory ให้ใส่ path folder ภาพ เช่น
D:\AI\Model\ชื่อ folder
Destination directory ให้ใส่ path folder ภาพที่ทำการสร้าง caption แล้ว เช่น
D:\AI\Model\ชื่อ folder\processed
ติ๊กถูกที่ Use BLIP for caption หลังจากนั้นกด Preprocess
โปรแกรมจะทำการสร้าง caption พร้อมกับ copy รูปไปไว้ใน Destination directory
แก้ไข caption
จบขั้นตอนการเตรียมภาพ
TEXTUAL INVERSION Training
- Copy Colab ไปทำเองส่วนตัว
- เชื่อม google drive เราไว้ดึงไฟล์
- Install/Update AUTOMATIC1111 repo (กด run ได้เลย)
-
Requirements(กด run ได้เลย)
Model Download/Load
- ถ้าไม่มีโมเดลให้ติ๊ก Redownload_the_original_model แล้วกด run ได้เลย
Start Stable-Diffusion
- กด run ได้เลยถ้าไม่มีโมเดลมันจะแจ้งเตือนให้ย้อนไปทำขั้นตอนที่แล้ว
แล้วดูไกด์จาก
Create embedding
number of vectors per token
2-3 = ต่ำกว่า 10 รูป
5-6 = 10-30 รูป
8-10 = 40-60 รูป
10-12 = 60-100 รูป
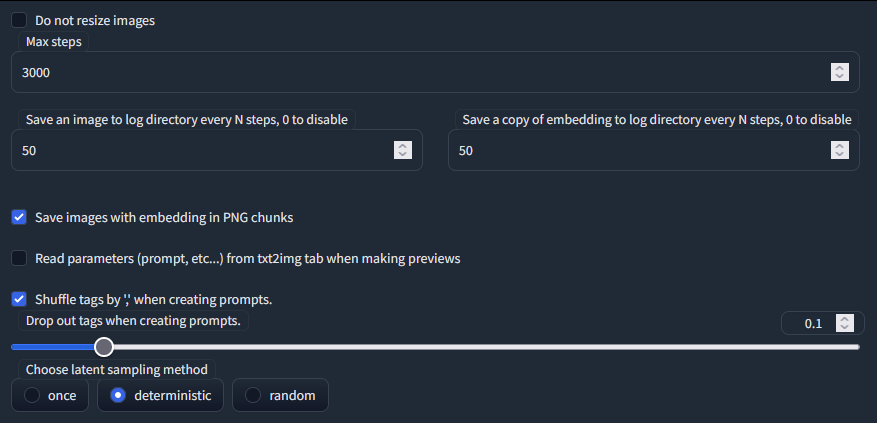
Train
ถ้ามี 30 รูป
Batch size 7
Gradient 5
Batch size x Gradient (x กันแล้วห้ามเกินจำนวนภาพที่มาทำ และ ห้าม Gradient มากกว่า Batch size)
7*5 = 35
progressive learning rates: 0.05:10, 0.02:20, 0.01:60, 0.005:200, 0.002:500, 0.001:3000, 0.0005