ฝึกโมเดลโดยใช้ Embedding Model Training
Embedding Model หรือ Textual Inversion แล้วแต่จะเรียก
ตัวอย่างจะเน้นการฝึกภาพบุคคล ใช้เป็น Elon
Workflow
เตรียมภาพเพื่อฝึกโมเดล
สมมุติว่าต้องการฝึกหน้าคน เช่นนาย A ให้เตรียมภาพไว้อย่างน้อย 10-20 รูป ก็เพียงพอโดย
- เน้นภาพคม ๆ คุณภาพสูง noise ไม่เยอะ
- พื้นหลังและสภาพแสงหลาย ๆ แบบ
- หลากหลายมุมไม่ใช่หน้าตรงอย่างเดียว เงยหน้า ก้มหน้า หันข้าง ได้หมด

ภาพยิ่งเยอะยิ่งใช้เวลาฝึกนาน และตัวอย่างพื้นหลังซ้ำเยอะไปหน่อย ยังไม่ดีพอ แต่ใช้ได้
หลังจากนั้นให้ resize ให้มีขนาด 512*512 โดยใช้โปรแกรมที่ถนัด หรือใช้
https://www.birme.net/?target_width=512&target_height=512
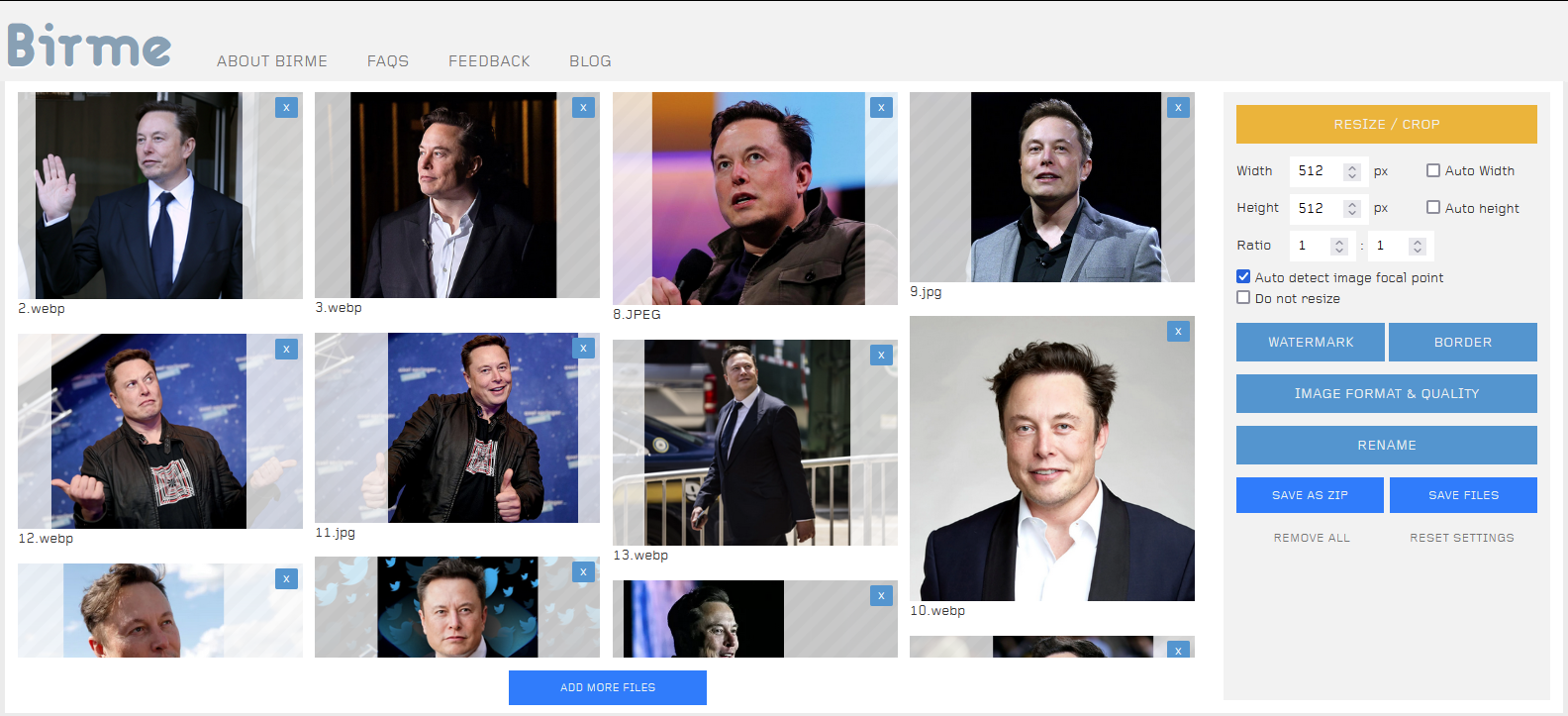
โดย resize ให้บุคคลอยู่ตรงกลางภาพหลังจากนั้นจึงจับใส่ folder ให้เรียบร้อยเช่น
D:\AI\Model\Elon
ถ้าใช้ birme ทำก็โหลดกลับมาเป็น zip แล้วค่อยแตกไฟล์
สร้าง caption
เปิด Stable Diffusion แล้วไปที่ Train > Preprocess images
Source directory ให้ใส่ path folder ภาพ เช่น
D:\AI\Model\Elon
Destination directory ให้ใส่ path folder ภาพที่ทำการสร้าง caption แล้ว เช่น
D:\AI\Model\Elon\processed
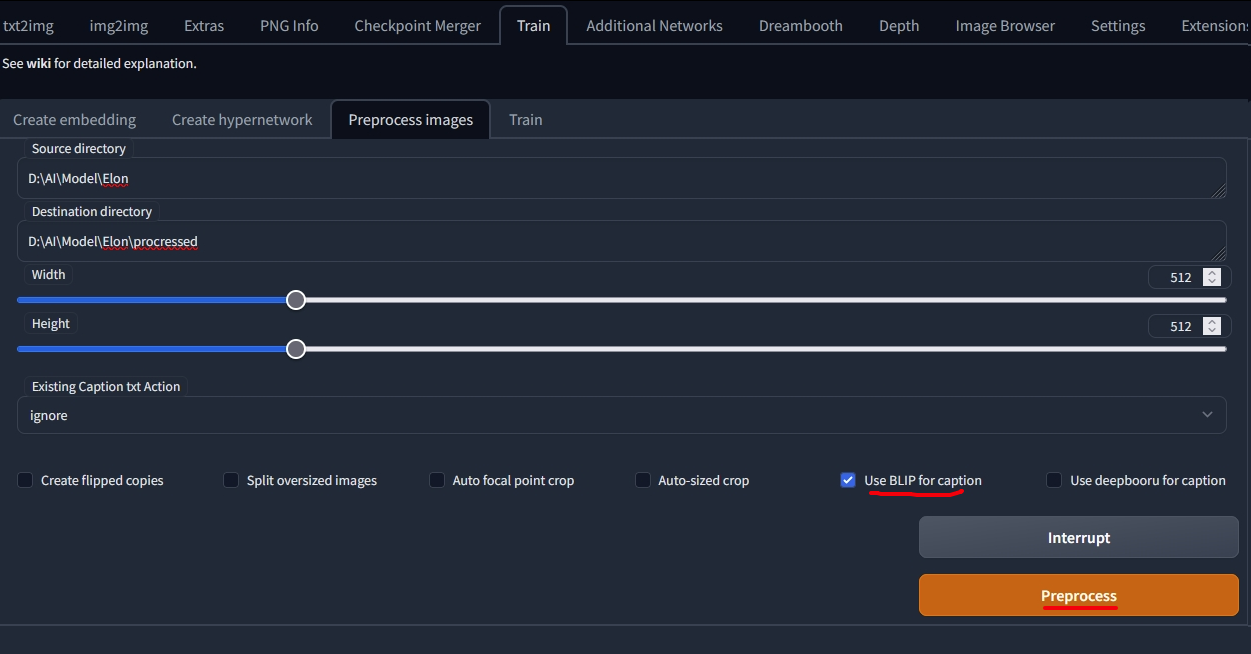
ติ๊กถูกที่ Use BLIP for caption หลังจากนั้นกด Preprocess
โปรแกรมจะทำการสร้าง caption พร้อมกับ copy รูปไปไว้ใน Destination directory
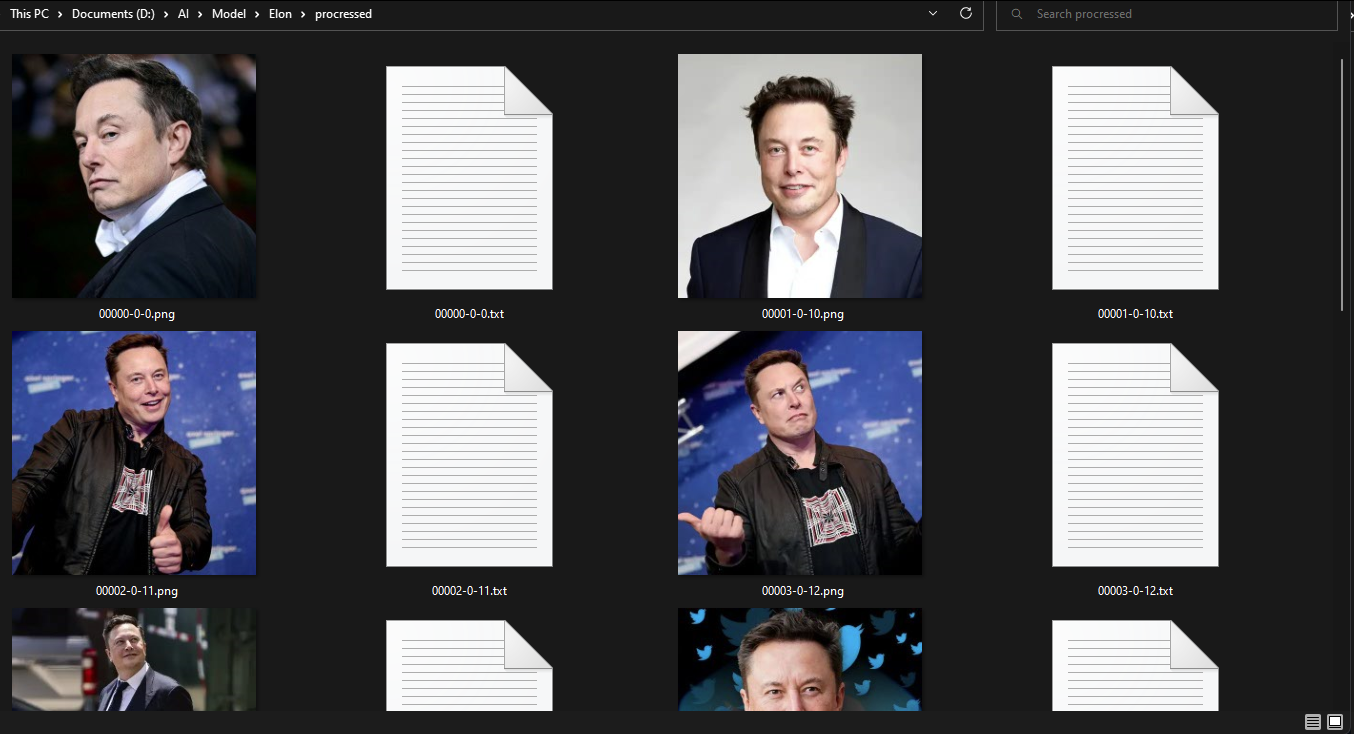
แก้ไข caption
จุดนี้จะทำหรือไม่ทำก็ได้แต่เพื่อคุณภาพก็ควรทำ อย่างน้อยเปิดไฟล์ .txt ขึ้นมาเช็ค เพื่อดูว่ามีคำที่มีความหมายแปลก ๆ และไม่ตรงกันใส่เข้ามาหรือไม่ โดยคำพวกนี้มันคือส่วนหนึ่งของ prompt ที่เราพิมพ์กรอกเข้าไปแล้ว AI มันจะอ่านแล้วส่งผลกับภาพด้วย
เช่นตัวอย่างสุ่มเจอคำที่ไม่ตรงกันกับรูปหรือ เยอะเกินไปคือภาพนี้
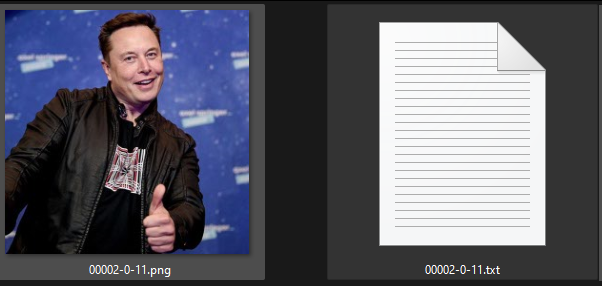
a man giving a thumbs up in front of a blue background with a sign that says,'i am not a fan of this man, i am not a fan of this guy, i am not a fan of
ควรลบข้อความใน txt เหลือแค่ a man giving a thumbs up in front of a blue background ก็พอ
หากต้องการเพิ่มรายละเอียดให้แน่นเป๊ะ ก็ใส่เพิ่มไปว่า wearing a black leather jacket เพื่อความสมบูรณ์
จบขั้นตอนการเตรียมภาพ
Model Training
สำหรับคนที่ต้องการใช้ Google Colab ให้อ่านตรงนี้ https://book.biribiri.me/books/stable-diffusion/page/stable-diffusion-model-training
ไกด์ยังไมได้เขียนจนเสร็จ ดูไกด์จาก Youtube ด้านล่างไปก่อน แต่มีไกด์ไลน์ตั้งค่าสำคัญ ๆ จดไว้ให้
Create embedding
number of vectors per token
- 2-3 = ต่ำกว่า 10 รูป
- 5-6 = 10-30 รูป
- 8-10 = 40-60 รูป
- 10-12 = 60-100 รูป
เน้นเฉพาะค่าที่จำเป็นต้องใช้งาน และต้องตั้งก่อนฝึก
Train
Embedding: ให้เลือกจาก Create embedding ที่เราสร้างไว้ก่อนหน้านี้
Embedding Learning rate: คือค่าที่กำหนดว่า AI เรียนรู้ภาพที่เราใส่ไปเร็วแค่ไหนยิ่งเร็วมากก็ยิ่งคุณภาพแย่ ยิ่งช้ามากก็จะเรียนเยอะเกินไปจนโมเดลนั้นพังสามารถตั้งได้ 2 แบบคือ
- แบบคงที่แนะนำให้ตั้งไว้ที่
0.004 - แบบขั้นบันไดให้ตั้งไว้ที่
0.05:10, 0.02:20, 0.01:60, 0.005:200, 0.002:500, 0.001:3000, 0.0005
ตัวอย่างจะแนะนำให้ใช้ Embedding Learning rate แบบขั้นบันไดซึ่งหมายถึงให้ AI เรียนรู้โครตสร้างของภาพเร็ว ๆ ในช่วงแรกๆ และมาเน้นรายละเอียดเจาะลึกในช่วงหลัง ๆ
Batch size: ตั้งให้สูงที่สุดเท่าที่ GPU จะรับไหว หาก Train แล้วไม่ไหวขึ้น CUDA Core Error ค่อยปรับลดลงมา
Gradient: accumulation step: เปรียบเสมือนตัวคูณของ Batch size และห้ามมีค่ามากกว่า Batch size
Google Colab น่าจะตั้งได้สูงสุดที่ Batch size 3 และ Gradient 1 เกินนั้นน่าจะ error ถ้าอยากเพิ่มก็ลองเอา
สมมุติว่าภาพที่นำมาฝึกมีทั้งหมด 20 รูป ก็ควรตั้ง Batch size*Gradient ไว้ที่ 20*1 หรือ 10*2 แล้วแต่ว่า GPU จะไหวแค่ไหน ถ้าไม่ไหวก็ปรับ Batch size ลงไปเรื่อย ๆ แต่เมื่อคูณแล้วห้ามเกินจำนวนรูปทั้งหมด ดังนั้น เราจะใช้ 7*3 ไม่ได้เพราะเกินจาก 20 รูป ให้ใช้ 6*3 แทน
Dataset directory: คือที่ตั้งของภาพใน folder process ที่ทำไว้แล้วเช่น
D:\AI\Model\ชื่อคน\processed
Dataset directory สำหรับ Google Colab อ่านที่นี่
ให้ดูตรงเมนู Files ด้านซ้าย gdrive > MyDrive แล้วกดไปยัง folder processed จะเห็นจุด 3 ตัวด้านหลังเป็นเมนู กด copy path ก็จะได้ path มาใส่ เช่น
/content/gdrive/MyDrive/AI/ชื่อบุคคล/processed
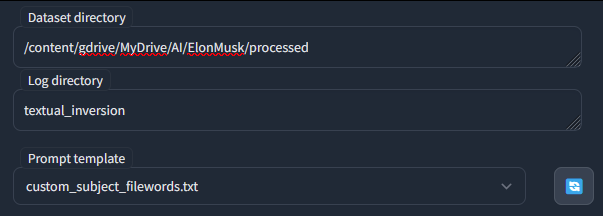
Prompt template: ให้เลือกไฟล์ template ที่สร้างไว้ จากตัวอย่างคือ custom_subject_filewords.txt
สร้างไฟล์ custom_subject_filewords.txt
จากตัวอย่างให้ไปที่ D:\AI\stable-diffusion-webui\textual_inversion_templates
ทำการ copy ไฟล์ subject_filewords.txt และเปลี่ยนชื่อเป็น custom_subject_filewords.txt (หรือะไรก็ได้ที่เข้าใจ)
เปิดไฟล์ Custom_subject_filewords.txt ลบทุกบรรทัดทิ้งให้หมด เหลือแค่ a photo of a [name], [filewords] ไว้ หลังจากนั้นให้เซฟ
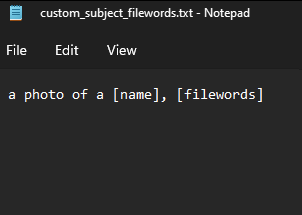
บรรทัดที่เหลือไว้หมายถึงเราจะใช้ prompt จากในไฟล์โดย
[name] หมายถึงข้อมูลจากใน txt ที่คู่กับรูปของเรา เช่นพวก a woman smile
[filewords] หมายถึงชื่อไฟล์ .pt ของเราจะใช้ในการเรียก prompt ซึ่งตรงนี้หลังจาก train เสร็จแล้วเราพอใจ .pt ไหน เราจะ rename ชื่ออะไรก็ได้แต่ให้เรียกใช้จากชื่อตามนั้น
Google Colab ก็ทำแบบเดียวกัน แต่ไปทำใน Google Drive หรืออะไรก็ช่างแล้วแต่ถนัดโดย path ไฟล์จะอยู่ใน
My Drive\sd\stable-diffusion-webui\textual_inversion_templates
เมื่อทำเสร็จแล้ว หากเปิด Colab ที่เชื่อมไว้แล้วให้รอสักครู่ แล้ว refresh เดี๋ยวไฟล์มันก็จะขึ้นมาเอง
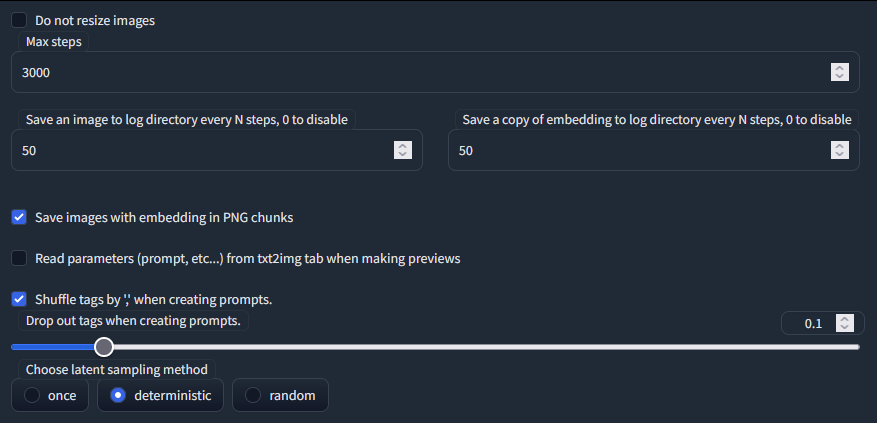
Max step: ให้ตั้งไว้เท่าไรก็ได้ แนะนำที่ 3000 เพราะเกินกว่านั้นส่วนมากโมเดลจะพัง (จากที่ลองมาบางที 2800 ก็เละแล้ว)
Save an image to log และ Save a copy to embedding: ให้ตั้งไว้ที่ 50 ซึ่งหมายถึง ให้เซฟตัวอย่างภาพและโมเดล ทุก ๆ การฝึก 50 step
Choose lantent sampling method: เลือก deterministic
เมื่อตั้งค่าทั้งหมดแล้วสามารถกด Train ได้เลย หาก error ซึ่งส่วนมากจะเป็น CUDA out of memory ให้กลับไปลดขนาด Batch size
โมเดลทั้งหมดจะอยู่ใน \stable-diffusion-webui\textual_inversion\ เรียงตามวันเดือนปี